
Use Grok patterns in AWS Glue to process streaming data into Amazon Elasticsearch Service | AWS Big Data Blog
Streaming Data Solutions on AWS

New – Serverless Streaming ETL with AWS Glue | AWS News Blog

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks | AWS Big Data Blog

Glue Streaming ETL Archives - Jayendra's Cloud Certification Blog

AWS Glue: Which Type? Spark or Spark Streaming | by Life-is-short--so--enjoy-it | Medium
 using LocalStack | Docs")
Schema Evolution with Glue Schema Registry and Managed Streaming for Kafka (MSK) using LocalStack | Docs

aws-kinesisstreams-gluejob - AWS Solutions Constructs

Streaming ETL With AWS Glue | ETL | AWS Glue | Kinesis Data Stream | Glue Crawler | Glue ETL Job - YouTube

Crafting serverless streaming ETL jobs with AWS Glue | AWS Big Data Blog
Glue Streaming Job timeout = null not working · Issue #25442 · hashicorp/terraform-provider-aws · GitHub

Serverless Data Lake: Storing and Analysing Streaming Data using AWS | by Shafiqa Iqbal | The Startup | Medium
GitHub - aws-samples/aws-glue-streaming-etl-with-delta-lake: Streaming ETL job cases in AWS Glue to integrate Delta Lake and creating an in-place updatable data lake on Amazon S3
![アップデート] 1行たりともコードは書かない!AWS GlueでストリーミングETLが可能になりました | DevelopersIO](https://dev.classmethod.jp/wp-content/uploads/2020/04/streametl21.png "アップデート] 1行たりともコードは書かない!AWS GlueでストリーミングETLが可能になりました | DevelopersIO")
アップデート] 1行たりともコードは書かない!AWS GlueでストリーミングETLが可能になりました | DevelopersIO

Amazon Web Services on X: "AWS Glue now allows you to consume data from streaming sources like Amazon Kinesis and Apache Kafka on the fly and make it available for analysis in

AWS Databases & Analytics on LinkedIn: AWS Glue Streaming ETL Auto Scaling is now generally available
GitHub - aws-samples/cloudformation-handle-dynamic-reference-in-awsglue- streaming: This blog explains a solution architecture to handle fast changing reference data stored in DynamoDB through an AWS Glue Streaming job

Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight - Blog - Amazon QuickSight Community

How to Stream Data to Vantage with Amazon Kinesis & AWS Glue

Ingest streaming data to Apache Hudi tables using AWS Glue and Apache Hudi DeltaStreamer | AWS Big Data Blog

Join a streaming data source with CDC data for real-time serverless data analytics using AWS Glue, AWS DMS, and Amazon DynamoDB | AWS Big Data Blog
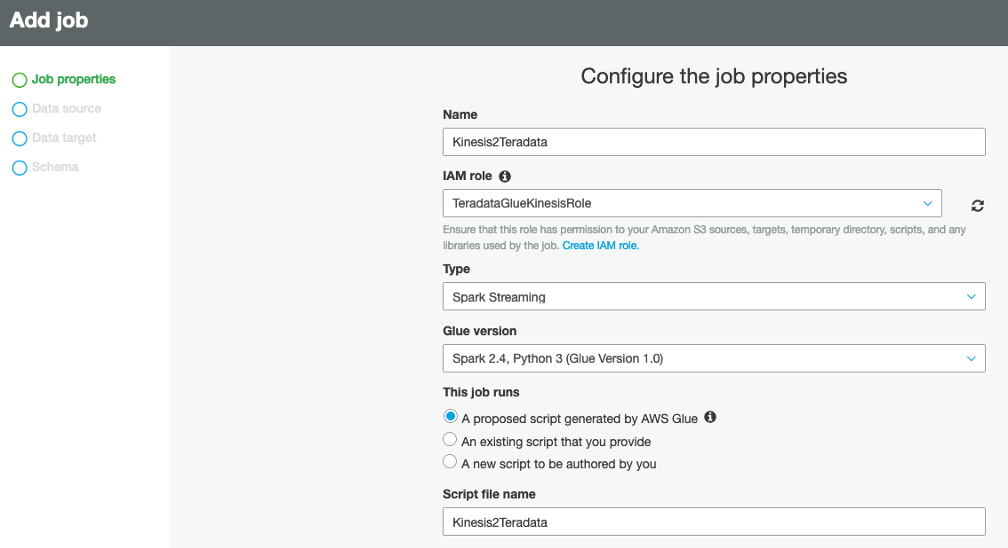.png?origin=fd "How to Stream Data to Vantage with Amazon Kinesis & AWS Glue")
How to Stream Data to Vantage with Amazon Kinesis & AWS Glue

Integrate AWS Glue Schema Registry with the AWS Glue Data Catalog to enable effective schema enforcement in streaming analytics use cases | AWS Big Data Blog

Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication | AWS Big Data Blog

AWS Tutorials - Using AWS Glue ETL Job with Streaming Data - YouTube

Stream data from relational databases to Amazon Redshift with upserts using AWS Glue streaming jobs | AWS Big Data Blog
 Streaming pipeline for clickstreams and power data lake with Apache Hudi and Query")